C++ State Machine, Three Ways: Switch/Case, GoF unique_ptr, and C++23 Variant — Benchmarked
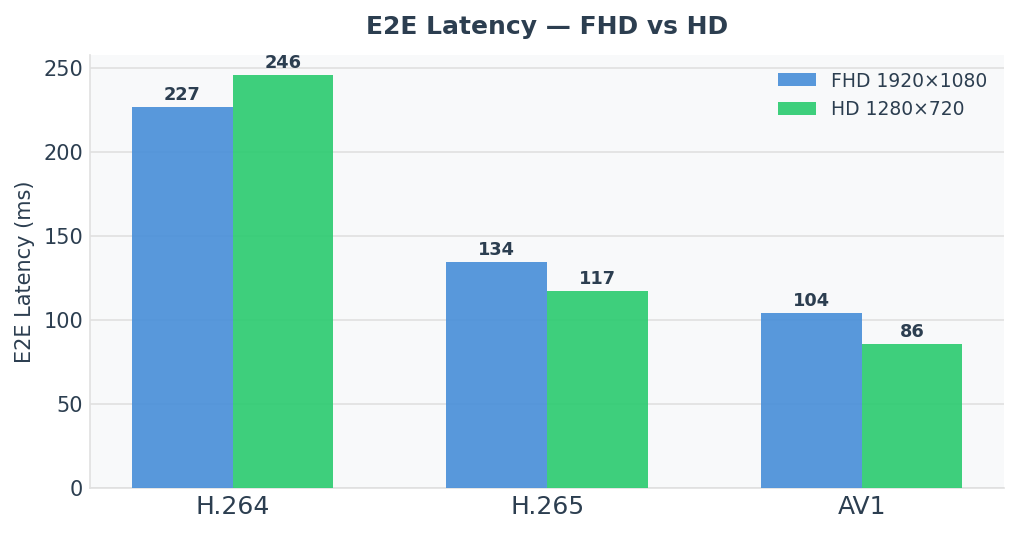
Three implementations of the same aircraft lifecycle FSM — a switch/case flat machine, the classic GoF State pattern with unique_ptr, and a C++23 compile-time variant/visit design — compiled with GCC 14 at -O2 -std=c++23, measured with nanobench, and linked to four live Godbolt sessions. The headline numbers: for a full seven-event mission cycle, the variant approach is 6× faster than OOP and switch/case is essentially free (the optimizer evaluates the constant-input trace at compile time). On the steady-state telemetry hot path, switch runs at 0.56 ns/event, variant at 1.07 ns/event, OOP at 1.20 ns/event. The culprit is not virtual dispatch — it is heap allocation. A follow-up section adds get_if chains and the [[likely]] attribute: on single-variant dispatch all four strategies land within 0.11 ns.