From a PyTorch Tracker to a Zero-Copy GStreamer Pipeline: Rebuilding SAM2.1/SAMURAI on Jetson, Step by Step
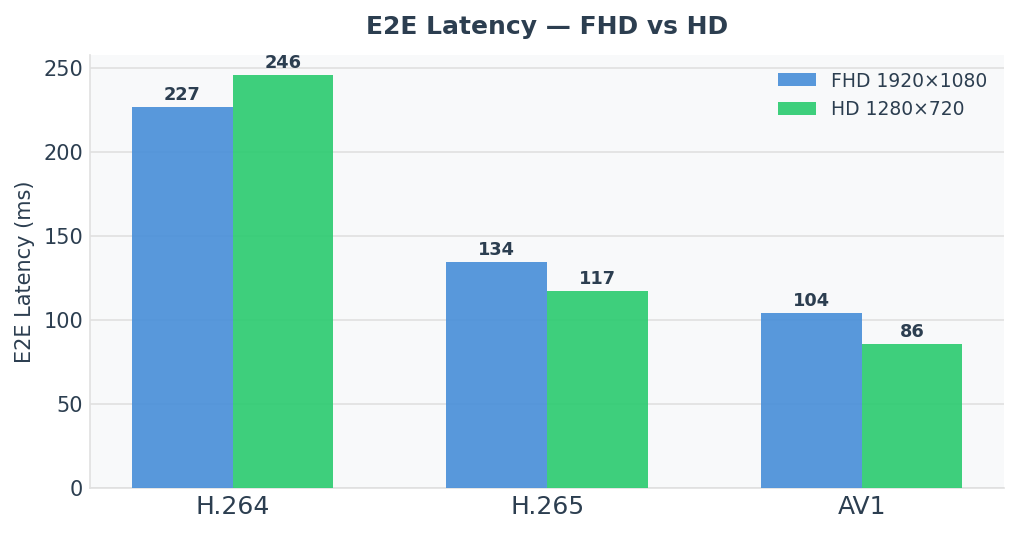
A long, hands-on account of turning a research-grade PyTorch visual tracker (SAM2.1 / SAMURAI) into a real-time, zero-copy GStreamer + CUDA + TensorRT pipeline on a Jetson Orin NX — decomposing the model into engines, exporting and parity-validating each one, porting the per-frame math to CUDA, packaging it as a GStreamer element, and squeezing 8 fps into 24 with queues and frame-skipping. Every stage is validated against a golden reference.